In my last post, I addressed the question of “What happens when you clone a FSMO role-holder”. This is another take on the same question of FSMO roles and how the new “Virtualized Domain Controller Safe Restore” feature in Windows Server 2012 impacts your disaster recovery plans and considerations. Please see the referenced link for a re-introduction to the new safety features introduced for virtualized Domain Controllers in Windows Server 2012.
This post focuses entirely on a scenario where a complete site disaster event has made the virtualized Domain Controllers unavailable, requiring us to recover (or restore) them, using your choice of disaster recovery mechanism. One such recovery mechanism is the VMware vCenter Site Recovery Manager (SRM). No, we will not talk SRM in this post).
As I have previously discussed in other posts, a change in the “state” of a virtualized Windows Server 2012 machine WILL result in a change in its VM-GenerationID (GenID). This change in GenID will automatically trigger a series of responses from the operating system. IF the VM is a Domain Controller (DC), the DC is compelled to do the following:
- Resets its InvocationID
- Discard its RID Pool
- Replace the GenID it had stored in its DIT with the new (changed) GenID that it has now received from the hypervisor
- Update its USN with its new InvocationID
- Obtain a new set of RID Pool
OK, there is more to it, but this will do for our purposes.
In a DR situation, we assume that “everything” is impacted. In this case, the Domain Controllers (DCs) are unavailable as a consequence of the disaster. Luckily for you, you have a DR site – an “off-site” – to which you have replicated copies of these DCs. You task is that much simplified – you just need to start “recovering” things, right? Well, sadly, not quite. Not if you have multiple Domain Controllers in the infrastructure.
In a multi-DC infrastructure, A DC wants to be able to establish communication with at least one other DC before is begins to consider itself sufficiently legitimate to begin performing its functions. Also, remember the steps that a Windows 2012 DC has to go through AFTER a change in state operation? Discard RID Pool, obtain new ones, etc? What if one of the affected DCs holds one (or more) of the FSMO roles? Yes, you guessed it …. we have a “situation”.
Let’s explain the conundrum….
When a DC powers on, it looks for other DC/DCs in the domain and tries to perform at least one valid inbound replication.
If this DC happens to be, say, the RID Master, then it has to be available quickly enough to be able to provide new RID pools to the other DCs that we are recovering. Or, let’s say it is the PDC emulator – we would want to be able to process GPOs. You get the picture. Now, don’t forget that this DC is required to perform at least one successful inbound replication before advertising these services. In a DR situation, if this DC is the first one to boot up, it will not be able to perform the required replication, so it will not advertize these services. When the other DCs come up, they, in turn, will be severely impacted by the non-availability of these services. The condition is also true if all the DCs are being simultaneously recovered. They will all go through the same “state changed” correction, and will simultaneously end up unable to inbound replicate. The DC that has discarded its RID Pool (thanks to VM-GenID) will remain RID-less for as long as this condition persist. For example, if your DR steps include the creation of new AD objects (say computer accounts) during the recovery, you are in a bind.
Windows Server 2012 DCs require special considerations and attention when attempting to recover in a DR situation. That, my friend, is the gist of this post.
Your recovery plan must include steps to account for these considerations. When recovering DCs and you end up in this condition, you have a couple of options for escaping from the hamster-wheel:
- Reboot the applicable FSMO role-holder after every DC has fully started
- Restart the Directory Service on the FSMO role-holder after its replication partner has fully started (NOTE: This may fail if you try to do this through the Services applet. Use the Powershell command (restart-service NTDS -force) instead.
- Force a manual replication from the FSMO role-holder to another DC
- Wait for a sufficiently long time for the DCs to retry the replication attempt on their own – not an attractive option in a “hair-on-fire” DR situation.
Better still, you can avoid this complication by simply locating a “warm” DC in your “off-site” location. In the DR situation described in this post, this “warm” DC will greatly simplify your recovery effort.
UPDATE:
Here are some screen shots of common events occurring during a DR situation.
The newly restored DC detects that its Generation-ID has changed. It then begins the process of “self healing”
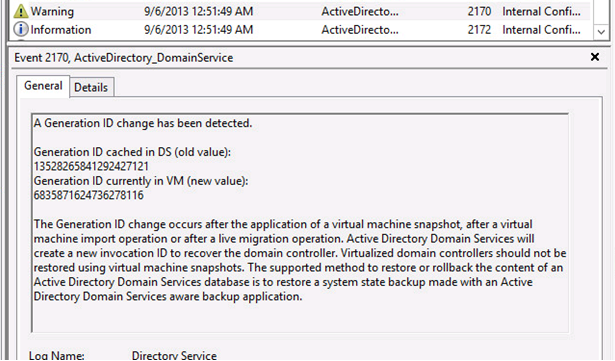
It discards its invocationID and assumes a new one.

It also discards its RID pool and looks towards a RID master to give it a new batch. Unfortunately, because the RID master itself is still undergoing recovery, it is unable to supply a new RID pool to this DC. In this condition, even if this DC has completely self-healed, it will not be able to perform any operation requiring the generation/allocation of RID. The same is true if the DC in question is the RID master itself but has not been able to perform a successful inbound replication with any of its replication partners.
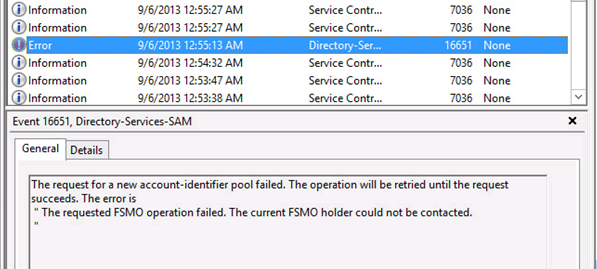
Here is what happens when you try to create a user account (for example) under the condition described above.

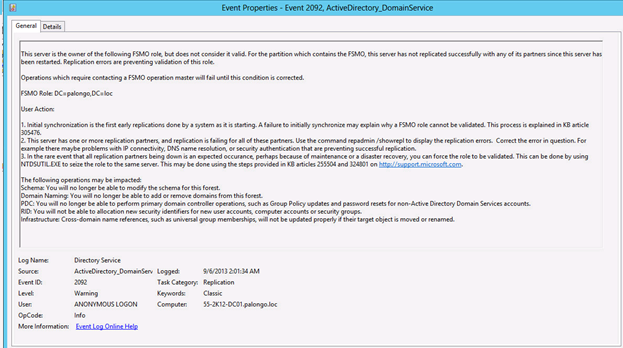
Here is a more detailed error log on the FSMO role-holder which has not been able to perform successful inbound replication.